AI Data Engineering / Hybrid RAG
CivicLens RAG — NYC 311 Operations Copilot
Local Hybrid RAG prototype for grounded NYC 311 documentation Q&A with citations, PostgreSQL/pgvector retrieval, sample analytics, and a Streamlit UI.
Scope is intentionally local: curated docs, local retrieval, cited answers, sample analytics summaries, and lightweight evaluation evidence.
Quick Scan
Project at a Glance
A concise view of what the prototype is, how it is reviewed, and what it proves.
Project type
AI Data Engineering / Hybrid RAG
Status
Completed Local Prototype
Retrieval
PostgreSQL + pgvector
Interface
Streamlit UI
Evaluation
pytest + 18-question set
Overview
Cited answers over documentation and runbooks
CivicLens RAG extends the NYC 311 lakehouse concept with a local AI data application for documentation Q&A and sample analytics answers.
Problem
Project docs, runbooks, data dictionaries, and analytics notes are often spread across files. That makes it hard to answer operational questions quickly while showing the source behind each answer.
Solution
CivicLens turns curated NYC 311 docs and runbooks into searchable chunks, stores embeddings in PostgreSQL/pgvector, retrieves relevant context, and returns cited answers in Streamlit.
Outcome
The prototype shows a complete local RAG workflow: ingestion, chunking, retrieval, citations, sample analytics routing, tests, CI, and an 18-question evaluation set.
Architecture
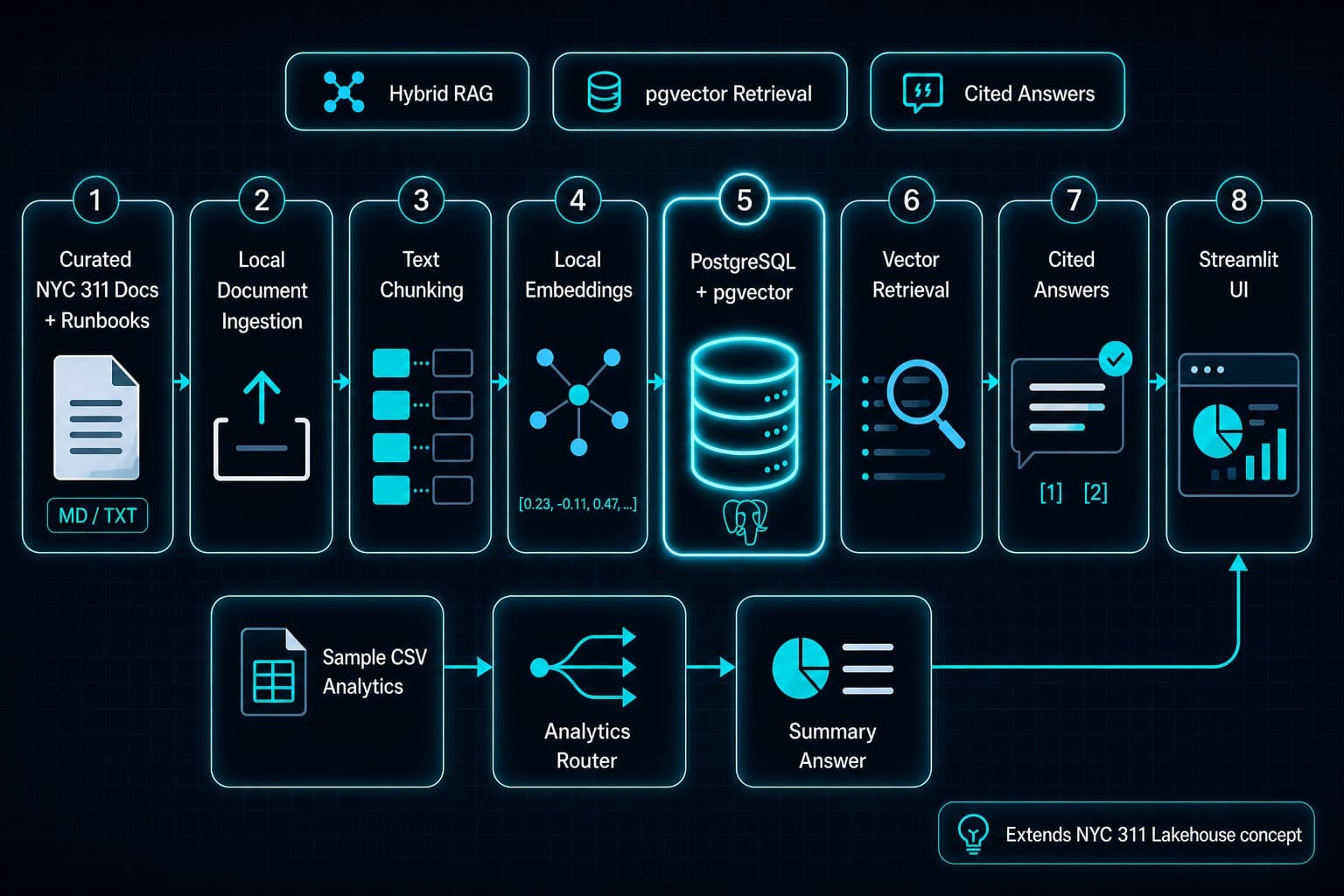
Local Hybrid RAG workflow with a sample analytics branch
The design separates documentation retrieval from predefined sample analytics summaries, then brings both paths into the local Streamlit interface.
Documentation Q&A path
Curated NYC 311 Docs + Runbooks
Local Document Ingestion
Text Chunking
Local Embeddings
PostgreSQL + pgvector
Vector Retrieval
Cited Answers
Streamlit UI
Secondary analytics path
Sample CSV Analytics
Analytics Router
Summary Answer
Streamlit UI
The analytics branch uses predefined sample CSV summaries, not production text-to-SQL or live NYC 311 data.
Technical Implementation
Local RAG system pieces
The implementation keeps the system reviewer-friendly and reproducible while demonstrating practical AI data engineering patterns.
Document Ingestion
Python ingestion loads curated NYC 311 documentation and runbooks into a local processing flow.
Chunking + Embeddings
Source text is split into chunks and embedded locally by default to keep the prototype reproducible.
PostgreSQL + pgvector Retrieval
PostgreSQL with pgvector stores embeddings and supports vector-similarity retrieval for relevant context.
Grounded Answers
The answer flow uses retrieved context only, returns citations, and handles no-answer cases explicitly.
Streamlit UI
A local browser UI lets reviewers ask documentation questions and inspect cited supporting context.
Sample Analytics
Predefined CSV summaries support sample analytics questions through a lightweight routing path.
Dockerized PostgreSQL/pgvector setup
The database layer is designed for local review with PostgreSQL and pgvector in Docker, so retrieval behavior can be tested without relying on a hosted service.
Evaluation and Quality
Focused checks for trustworthy prototype behavior
The project includes focused tests and an evaluation set to make RAG behavior visible rather than implied.
- pytest coverage for ingestion, retrieval, routing, and answer behavior
- GitHub Actions CI for repeatable local checks
- 18-question evaluation set for reviewer-facing validation
- Checks for retrieval relevance, citation behavior, analytics routing, and no-answer handling
Reviewer evidence
The checks make local prototype behavior easier to inspect: retrieval relevance, citations, analytics routing, and no-answer handling are tested directly.
Honest Scope
Limitations are explicit
The case study separates prototype evidence from production claims.
- Local project only; it is not deployed.
- Not connected to live NYC 311 data.
- Not production text-to-SQL.
- OpenAI support is optional and disabled by default.
- Evaluation is lightweight and not a production benchmark.
What This Demonstrates
Recruiter-relevant AI data engineering signals
The project shows how data engineering assets can become a grounded local AI application without overstating deployment scope.
Hybrid RAG architecture
PostgreSQL/pgvector vector retrieval
Source-grounded answers with citations
Local AI data application design
Evaluation-minded AI engineering
Documentation-first data engineering workflow
Explore the Project
Review the repo, architecture, and screenshots
Start with the repository README, then review the architecture notes and screenshot evidence. No live demo link is provided because this is scoped as a completed local prototype.