AZURE DATA ENGINEERING
NYC 311 Service Requests Lakehouse
Azure-first medallion lakehouse for NYC 311 operational analytics, transforming raw API data into analytics-ready bronze, silver, and gold datasets.
- Azure Data Factory -> ADLS Gen2 -> Databricks pipeline with proven raw landing and medallion processing
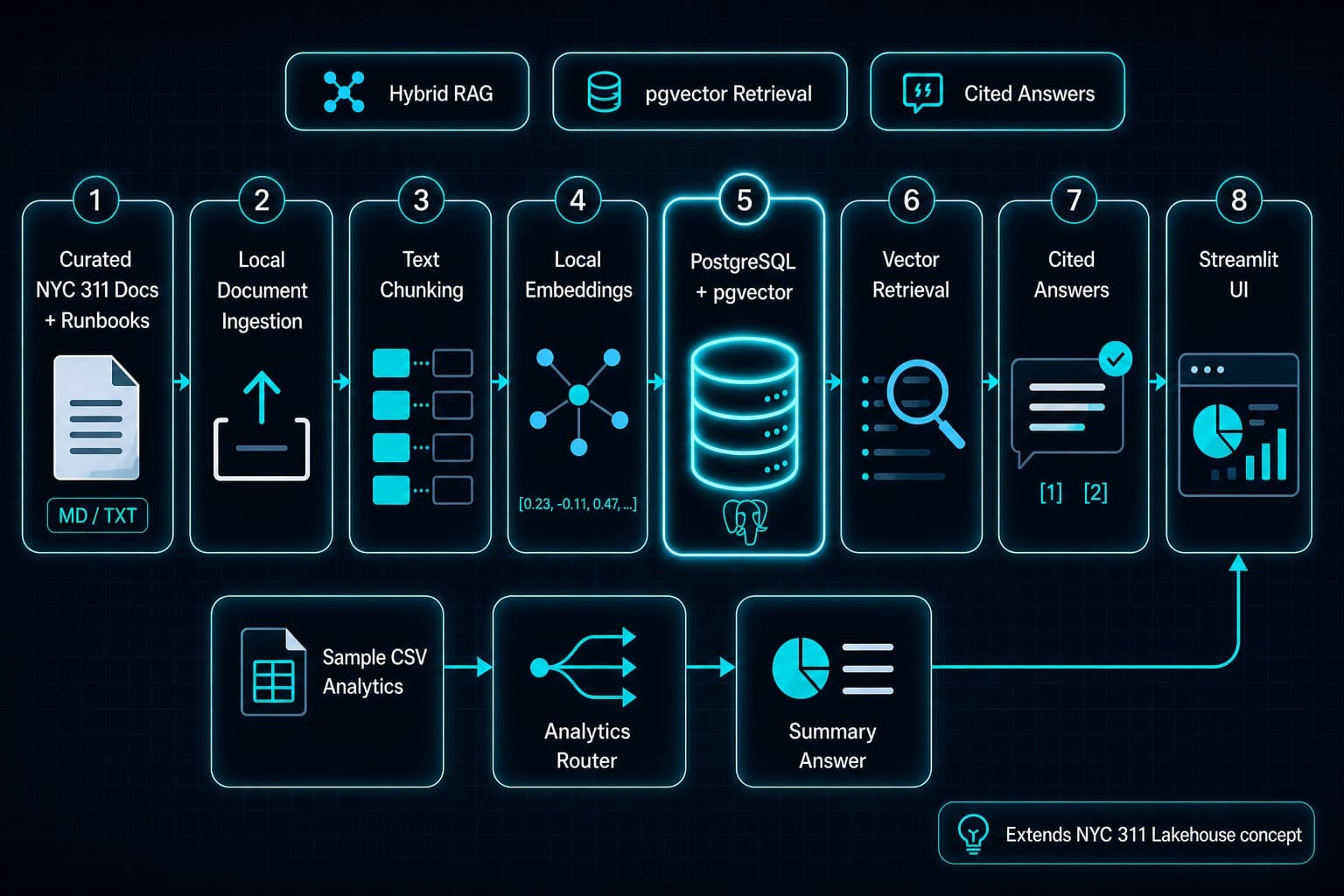
- Reusable data quality checks, dimensional models, and reporting marts
- Architecture notes, runbooks, SQL assets, notebook exports, and cloud execution proof
Azure Data FactoryADLS Gen2DatabricksPySparkDelta LakePythonSQLPower BIGitHub Actions